集合
集合命名空间:
- using System.Collections;(非泛型集合)
- using System.Collections.Generic;(泛型集合)
常用集合
“类似数组”集合:ArrayList、List
“键值对”集合(“哈希表”集合):Hashtable、Dictionary
“堆栈”集合:Stack、Stack
(LIFO)Last In First Out “可排序键值对”集合:(插入、检索没有“哈希表”集合高效)
- SortedList、SortedList
- SortedDictionary
- SortedList、SortedList
Set 集合:无序、不重复。HashSet
,可以将 HashSet类视为不包含值的 Dictionary集合。与List 类似。SortedSet (.net4.0支持,有序无重复集合)
“双向链表”集合:LinkedList
,增删速度快。
ArrayList、Hashtable、List
数组特点:类型统一、长度固定。
集合常用操作 添加、遍历、移除
命名空间System.Collections
ArrayList 可变长度数组,使用类似于数组
属性 Capacity(集合中可以容纳元素的个数,翻倍增长); Count(集合中实际存放的元素的个数。)
方法
- Add(10) AddRange(ICollection c) Remove() RemoveAt() Clear()
- Contains() ToArray() Sort() 排序\Reverse();//反转
Hashtable 键值对的集合,类似于字典,Hashtable在查找元素的时候,速度很快。
- Add(object key,object value);
- hash[“key”]
- hash[“key”]=“修改”;
- .ContainsKey(“key”);
- Remove(“key”);
- 遍历:
- hash.Keys
- hash.Values/DictionaryEntry
键值对集合中的“键”,绝对不能重复。
//Hashtable不限制键值的数据类型
//hashtable不能添加重复键
//Hashtable 内部也是使用数组实现的,key与索引下标一一对应(是通过key算出来的索引下标)
Dictionary实现
Dictionary和hashtable用法有点相似,他们都是基于键值对的数据集合,但实际上他们内部的实现原理有很大的差异,
先简要概述一下他们主要的区别,稍后在分析Dictionary内部实现的大概原理。
区别:1,Dictionary支持泛型,而Hashtable不支持。
2,Dictionary没有装填因子(Load Facto)概念,当容量不够时才扩容(扩容跟Hashtable一样,也是两倍于当前容量最小素数),Hashtable是“已装载元素”与”bucket数组长度“大于装载因子时扩容。
3,Dictionary内部的存储value的数组按先后插入的顺序排序,Hashtable不是。
4,当不发生碰撞时,查找Dictionary需要进行两次索引定位,Hashtable需一次,。
Dictionary采用除法散列法来计算存储地址,想详细了解的可以百度一下,简单来说就是其内部有两个数组:buckets数组和entries数组(entries是一个Entry结构数组),entries有一个next用来模拟链表,该字段存储一个int值,指向下一个存储地址(实际就是bukets数组的索引),当没有发生碰撞时,该字段为-1,发生了碰撞则存储一个int值,该值指向bukets数组.
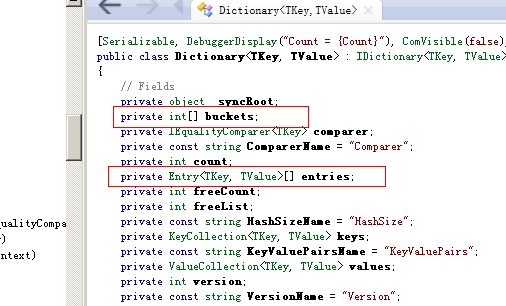

下面跟上次一样,按正常使用Dictionary时,看内部是如何实现的。
一,实例化一个Dictionary, Dictionary
a,调用Dictionary默认无参构造函数。
b,初始化Dictionary内部数组容器:buckets int[]和entries );
);
二,向dic添加一个值,dic.add(“a”,”abc”);
a,将bucket数组和entries数组扩容3个长度。
b,计算”a”的哈希值,
c,然后与bucket数组长度(3)进行取模计算,假如结果为:2
d,因为a是第一次写入,则自动将a的值赋值到entriys[0]的key,同理将”abc”赋值给entriys[0].value,将上面b步骤的哈希值赋值给entriys[0].hashCode,
entriys[0].next 赋值为-1,hashCode赋值b步骤计算出来的哈希值。
e,在bucket[2]存储0。
三,通过key获取对应的value, var v=dic[“a”];
a, 先计算”a”的哈希值,假如结果为2,
b,根据上一步骤结果,找到buckets数组索引为2上的值,假如该值为0.
c, 找到到entriys数组上索引为0的key,
1),如果该key值和输入的的“a”字符相同,则对应的value值就是需要查找的值。
2) ,如果该key值和输入的”a”字符不相同,说明发生了碰撞,这时获取对应的next值,根据next值定位buckets数组(buckets[next]),然后获取对应buckets上存储的值在定位到entriys数组上,……,一直到找到为止。
3),如果该key值和输入的”a”字符不相同并且对应的next值为-1,则说明Dictionary不包含字符“a”。**
Dictionary里的其他方法就不说了,各位可以自己去看源码,下面来通过实验来对比Hashtable和Dictionary的添加和查找性能,
1,添加元素速度测评。
循环5次,每次内部在循环10次取平均值,PS:代码中如有不公平的地方望各位指出,本人知错就改。
a,值类型
 ;)
;)
1 | static void Main(string[] args) |
;)
结果:
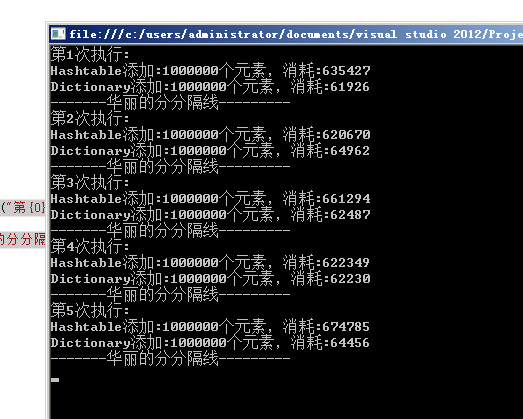
通过运行结果来看,HashTable 速度明显慢于Dictionary,相差一个数量级。我个人分析原因可能为:
a,Hashtable不支持泛型,我向你添加的int类型会发生装箱操作,而Dictionary支持泛型。
b,Hashtable在扩容时会先new一个更大的数组,然后将原来的数据复制到新的数组里,还需对新数组里的key重新哈希计算(这可能是最性能影响最大的因素)。而Dictionary不会这样。
b,引用类型
;)
1 | static void Main(string[] args) |
;)

Dic速度还是比Hashtable快,但没有值类型那么明显,这个测试可能有不准的地方。
2,查找速度测评(两种情况:值类型和引用类型)
1 值类型
;)
1 | static void Main(string[] args) |
;)
运行结果

2,引用类型
;)
1 | 1 static void Main(string[] args) |
;)
运行结果

根据上面实验结果可以得出:
a,值类型,Hashtable和Dictionary性能相差不大,Hashtable稍微快于Dictionary.
b,引用类型:Hashtable速度明显快于Dictionary。
HashTable实现
先例举几个问题:1,Hashtable为什么速度查询速度快,而添加速度相对慢,且其添加和查询速度之比相差一个数量等级?
2,装填因子( Load Factor)是什么,hashtable默认的装填因子是多少?
3,hashtable里的元素是顺序排序的吗?
4,hashtable内部的数据桶(数组)默认长度多少,其长度为什么只能是素数?
Hashtable中的数据实际存储在内部的一个数据桶里(bucket结构数组),其和普通的数组一样,容量固定,根据数组索引获取值。
下面从正常使用Hashtable场景看内部是如何实现的,内部都做了哪些工作。
一,new一个Hashtable,Hashtable ht=new Hashtable();
Hashtable有多个构造函数,常用的是无参构造函数:Hashtable ht=new Hashtable(),在new一个hashtable时,其内部做了如下工作:调用Hashtable(int capacity,float loadFactor),其中capacity为:0,loadFactor为:1,然后初始化bocket数组大小为3,装载因子为0.72(该值是微软权衡后给的值),如下图所示,该图截取Reflector

二,向Hashtable添加一个元素,ht.Add(“a”,”123”)
1,判断当前Hashtable :ht的元素个数与bucket数组之比是否超过装载因子0.72,
1)小于0.72:对a进行哈希取值,然后将得到的值与bucket数组长度进行取模计算,将取模的结果插入到bucket数组对应索引,将“123”赋值其value.
因为哈希值可能会重复(不明白的百度一下),从而导致地址冲突,Hashtable 采用的是 “开放定址法” 处理冲突, 具体行为是把 HashOf(k) % Array.Length 改为 (HashOf(k) + d(k)) % Array.Length , 得出另外一个位置来存储关键字 “a” 所对应的数据, d 是一个增量函数. 如果仍然冲突, 则再次进行增量, 依此循环直到找到一个 Array 中的空位为止。
2) 大于0.72:对bucket数组进行扩容,a, 新建一个数组(该数组的大小为两倍于当前容量最小的素数,比如当前数组长度是3,那么新数组长度为7)。
b,将原来数组元素拷贝到新的数组中,因为bocket数组长度变了,所以需要对所有key重新哈希计算(这是影响hashtable性能的重要因素)。
c, 进行上面a步骤。
三,通过key获取Hashtable对应的value,var v=ht[“a”];
1) 计算”a”的哈希值。
2)将计算的结果与bocket数组长度进行取模计算,因为哈希值可能会冲突,所以类似定位索引上的key可能与输入的key不相同,这时继续查找下一个位置。。。。。
3)取模计算结果即是存储在bocket数组上”123”的索引。
Hashtable还有很多方法,比如Clear ,Remove ,ContainsKey,ContainsValue等方法,因篇幅有限这里就不一一介绍了。
写到这里来回答一下篇幅开头的几个问题。
1,Hashtable查询速度快是因为内部是基于数组索引定位的,稍微消耗性能的是取KEY的哈希值,添加性能相对查询慢是因为:a,添加元素时可能会地址冲突,需要重新定位地址 。 b,扩容后 数组拷贝,重新哈希计算旧数组所有key。
2, 装填因子是Hashtable“已存元素个数/内部bucket数组长度”,这个比值太大会造成冲突概率增大,太小会造成空间的浪费。默认是0.72,该值是微软经过大量实验得出的一个比较平衡的值,装填因子范围 0.1<loadFactor<1,否则抛出ArgumentOutOfRangeException异常。
3,不是顺序的(各位看了文章应该知道为什么不是顺序的了吧?)
4,默认长度是3,我看的是.net framework 4.5版本反编译的代码,其他版本的.net framework不确定是不是这个值。为什么扩容的数组长度一定要是素数呢?因为素数有一个特点,只能被自己和1整除,如果不是素数那么在进行取模计算的时候可能会出现多个值。如下图: